Fighting CUDA paralelism for printing vectors
Aug 062019Parallel programming has its challanges. For my case I did not find very usefull to use a debbuger and also for the quick fix I did not want to extract the G matrix to print it on the CPU as I use only one row for each thread and store it in the "__shared__" memory (see CUDA Memory model).
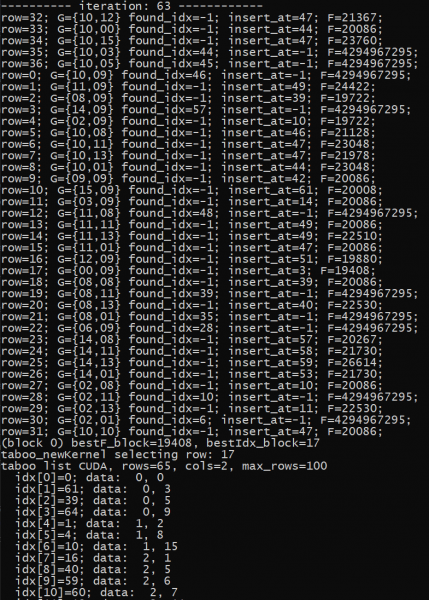
Naive printing as I would do on the CPU did not do the tick at all... :-)

I did not find an sprintf implementation quickly (cuda does not provide one) and decided to tackle the problem on my own. As I know how many digits I need to print (here in the example just 2 at most).
It helped me find the bug that eluded me for some time and I might write it as a function to use for my further debugging.
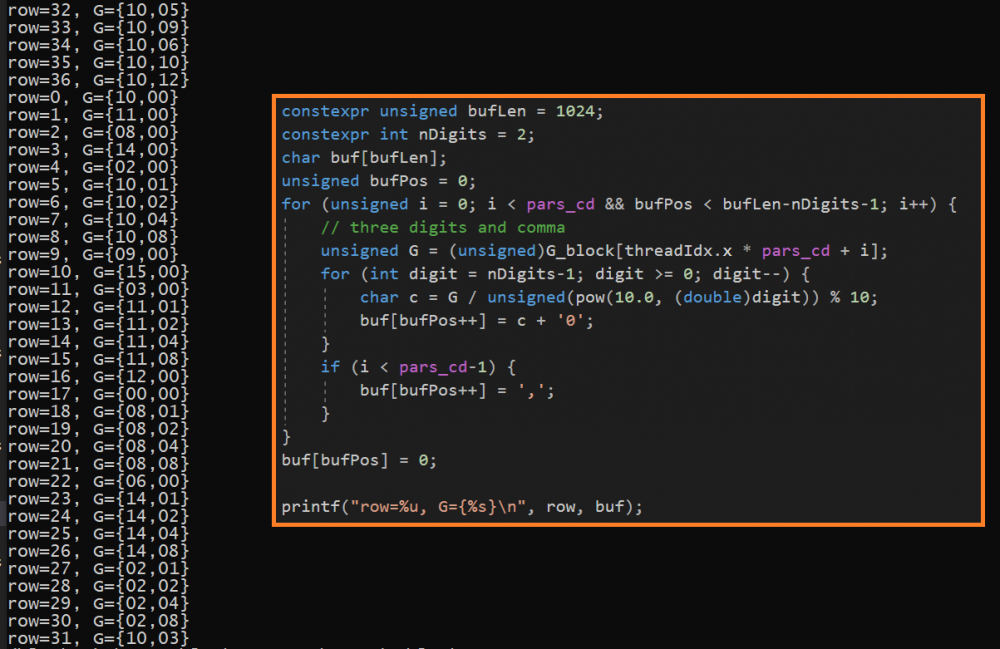
(pow must get double arguments, or it prints error like "cannot call host function from __global__ device function")
My actual debug printing looks like this. Semicolon separated values can be easily analyzed with python scripts or Calc/Excel.